Get Started
Haystack is an open-source Python framework that helps developers build LLM-powered custom applications. In March 2024, we released Haystack 2.0, a significant update. For more information on Haystack 2.0, you can also read the announcement post.
Installation
Use pip to install Haystack:
pip install haystack-ai
For more details, refer to our documentation.
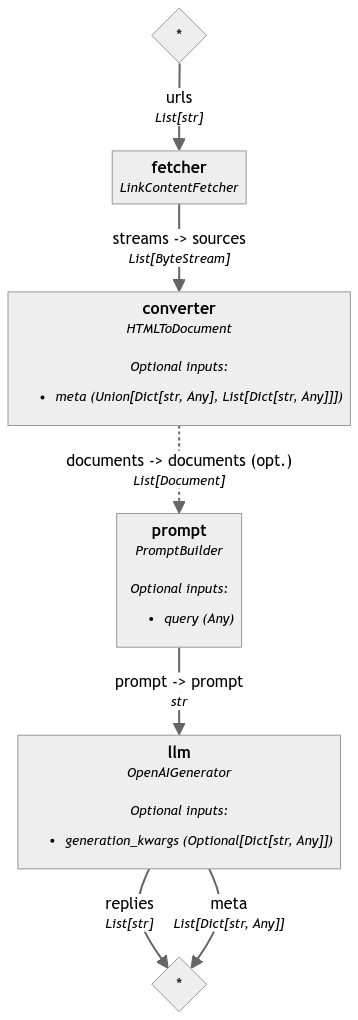
Ask Questions to a Webpage
This is a very simple pipeline that can answer questions about the contents of a webpage. It uses GPT-3.5-Turbo with the OpenAIGenerator.
Run the following Quickstart or the equivalent Corresponding Pipeline below. See the pipeline visualized in Pipeline Graph.
First, install Haystack:
pip install haystack-ai trafilatura
import os
from haystack import Pipeline, PredefinedPipeline
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
pipeline = Pipeline.from_template(PredefinedPipeline.CHAT_WITH_WEBSITE)
result = pipeline.run({
"fetcher": {"urls": ["https://haystack.deepset.ai/overview/quick-start"]},
"prompt": {"query": "Which components do I need for a RAG pipeline?"}}
)
print(result["llm"]["replies"][0])
First, install Haystack:
pip install haystack-ai trafilatura
import os
from haystack import Pipeline
from haystack.components.fetchers import LinkContentFetcher
from haystack.components.converters import HTMLToDocument
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
fetcher = LinkContentFetcher()
converter = HTMLToDocument()
prompt_template = """
According to the contents of this website:
{% for document in documents %}
{{document.content}}
{% endfor %}
Answer the given question: {{query}}
Answer:
"""
prompt_builder = PromptBuilder(template=prompt_template)
llm = OpenAIGenerator()
pipeline = Pipeline()
pipeline.add_component("fetcher", fetcher)
pipeline.add_component("converter", converter)
pipeline.add_component("prompt", prompt_builder)
pipeline.add_component("llm", llm)
pipeline.connect("fetcher.streams", "converter.sources")
pipeline.connect("converter.documents", "prompt.documents")
pipeline.connect("prompt.prompt", "llm.prompt")
result = pipeline.run({"fetcher": {"urls": ["https://haystack.deepset.ai/overview/quick-start"]},
"prompt": {"query": "Which components do I need for a RAG pipeline?"}})
print(result["llm"]["replies"][0])
Build Your First RAG Pipeline
To build modern search pipelines with LLMs, you need two things: powerful components and an easy way to put them together. The Haystack pipeline is built for this purpose and enables you to design and scale your interactions with LLMs. Learn how to create pipelines here.
By connecting three components, a Retriever, a PromptBuilder and a Generator, you can build your first Retrieval Augmented Generation (RAG) pipeline with Haystack.
Try out how Haystack answers questions about the given documents using the RAG approach 👇
Install Haystack:
pip install haystack-ai
import os
from haystack import Pipeline, PredefinedPipeline
import urllib.request
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
urllib.request.urlretrieve("https://archive.org/stream/leonardodavinci00brocrich/leonardodavinci00brocrich_djvu.txt",
"davinci.txt")
indexing_pipeline = Pipeline.from_template(PredefinedPipeline.INDEXING)
indexing_pipeline.run(data={"sources": ["davinci.txt"]})
rag_pipeline = Pipeline.from_template(PredefinedPipeline.RAG)
query = "How old was he when he died?"
result = rag_pipeline.run(data={"prompt_builder": {"query":query}, "text_embedder": {"text": query}})
print(result["llm"]["replies"][0])
Install Haystack:
pip install haystack-ai
import os
import urllib.request
from haystack import Pipeline
from haystack.document_stores.in_memory import InMemoryDocumentStore
from haystack.components.retrievers import InMemoryEmbeddingRetriever
from haystack.components.converters import TextFileToDocument
from haystack.components.preprocessors import DocumentCleaner, DocumentSplitter
from haystack.components.embedders import OpenAIDocumentEmbedder, OpenAITextEmbedder
from haystack.components.writers import DocumentWriter
from haystack.components.builders import PromptBuilder
from haystack.components.generators import OpenAIGenerator
os.environ["OPENAI_API_KEY"] = "Your OpenAI API Key"
urllib.request.urlretrieve("https://archive.org/stream/leonardodavinci00brocrich/leonardodavinci00brocrich_djvu.txt",
"davinci.txt")
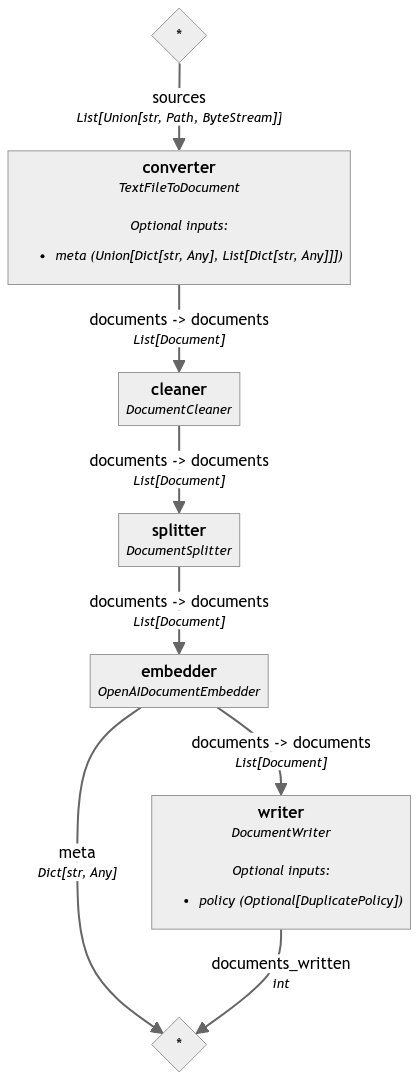
document_store = InMemoryDocumentStore()
text_file_converter = TextFileToDocument()
cleaner = DocumentCleaner()
splitter = DocumentSplitter()
embedder = OpenAIDocumentEmbedder()
writer = DocumentWriter(document_store)
indexing_pipeline = Pipeline()
indexing_pipeline.add_component("converter", text_file_converter)
indexing_pipeline.add_component("cleaner", cleaner)
indexing_pipeline.add_component("splitter", splitter)
indexing_pipeline.add_component("embedder", embedder)
indexing_pipeline.add_component("writer", writer)
indexing_pipeline.connect("converter.documents", "cleaner.documents")
indexing_pipeline.connect("cleaner.documents", "splitter.documents")
indexing_pipeline.connect("splitter.documents", "embedder.documents")
indexing_pipeline.connect("embedder.documents", "writer.documents")
indexing_pipeline.run(data={"sources": ["davinci.txt"]})
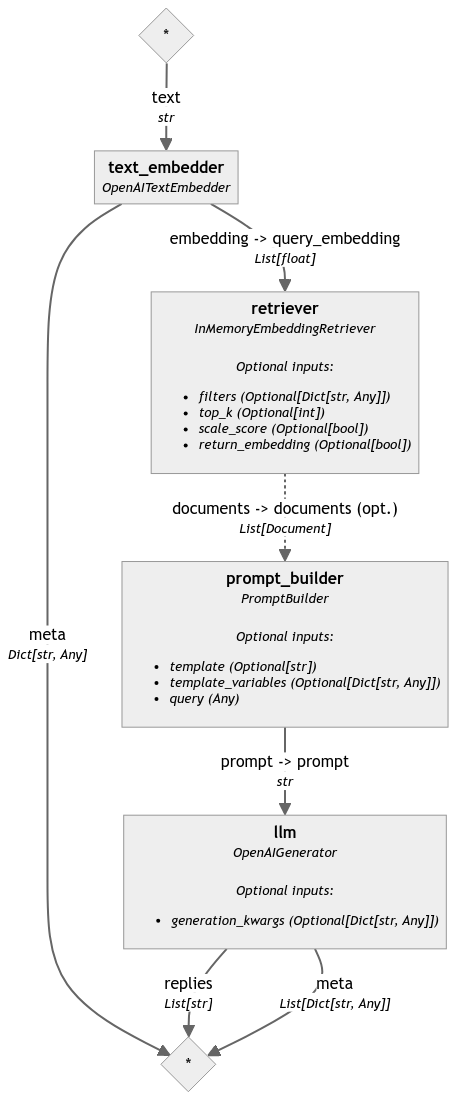
text_embedder = OpenAITextEmbedder()
retriever = InMemoryEmbeddingRetriever(document_store)
template = """Given these documents, answer the question.
Documents:
{% for doc in documents %}
{{ doc.content }}
{% endfor %}
Question: {{query}}
Answer:"""
prompt_builder = PromptBuilder(template=template)
llm = OpenAIGenerator()
rag_pipeline = Pipeline()
rag_pipeline.add_component("text_embedder", text_embedder)
rag_pipeline.add_component("retriever", retriever)
rag_pipeline.add_component("prompt_builder", prompt_builder)
rag_pipeline.add_component("llm", llm)
rag_pipeline.connect("text_embedder.embedding", "retriever.query_embedding")
rag_pipeline.connect("retriever.documents", "prompt_builder.documents")
rag_pipeline.connect("prompt_builder", "llm")
query = "How old was Leonardo when he died?"
result = rag_pipeline.run(data={"prompt_builder": {"query":query}, "text_embedder": {"text": query}})
print(result["llm"]["replies"][0])
Indexing Pipeline
RAG Pipeline
For a hands-on guide on how to build your first RAG Pipeline with Haystack 2.0, see our tutorial.